Визуальная отладка в DDD
Автор: (C) Wolfgang Mauerer
Перевод: (C) Александр Михайлов
Введение
Людям свойственно ошибаться. Программисты -- люди. Следовательно, программисты ошибаются. Невероятная сложность и запутанная логика этого утверждения могли бы, вероятно, породить годы обсуждений в стане философов :) ,но если не парить в мире утонченных идей, то из этого утверждения лишь следует одна непреложная истина: Все написанные людьми программы полны ошибок. Несмотря на то, что кто-то кое-где (у нас порой -- прим. ред.) до сих пор полагает программирование занятием механическим и неумным и что, будучи достаточно усердным и тщательно все планируя, все на свете можно запрограммировать без ошибок -- более верный подход может показаться программистам губительным. А именно: ничего и никогда не работает так, как надо; все программы полны ошибок; спецификации неверны, а рализация делает прямо противоположное ожидаемому. Это не наезд на программистов:), как раз наоборот: программирование -- сложная, требующяя огромного напряжения работа, ошибок избежать невозможно даже лучшим программистам -- совсем без ошибок запрограммировать можно только самые простые вещи. Осознание истинной важности ошибок, или, правильнее, работоспособный способ нахождения и исправления ошибок в жизненном цикле программного продукта -- вот задача, важность которой невозможно переоценить. Нахождение ошибок не только неизбежная часть цикла разработки программного обеспечения, но и важная составляющая "жизненного пути" любой программы.
Очевидно, что ошибки в программных системах должны быть найдены, и что для решения этой задачи программисту нужны хорошие инструменты. Как должно быть известно большинству из вас, существует очень хороший отладчик, свободно предоставляемый в рамках проекта GNU (а где же еще?). Т.к. именно люди из GNU отвечают за самый важный для Линукс компилятор -- gnu c, то в случае, когда нужно найти и обезвредить гадкие ошибки в ваших программах, именно из этих двух программ формируется "бесстрашная группа захвата". Те, кто уже пользовались отладчиком GDB, знакомы с его спартанским интерфейсом: не то, что бы он был особенно плохим, но он и не слишком хорош. Даже если вы дружите с командной строкой и текстовым интерфейсом (как автор данной статьи), использовать такую форму взаимодействия с отладчиком не слишком весело, а иногда может стать просто мучительным занятием, особенно при отладке больших систем со сложными структурами данных. Такой текстовый интерфейс, возможно, неплохо приспособлен для пошагового прохода по программе, проверки значений простых переменных или определенных условий, но это, конечно, не оптимальный выбор для современной, простой и эффективной отладки развитых структур данных, тесно переплетенных друг с другом.
Следовательно, нам нужен графический интерфейс, и проект GNU вновь предлагает нужное нам: DDD, Data Display Debugger (отладчик с визуальным отображение данных). DDD -- это графический интерфейс, написанный Andreas Zeller и Dorothea Luetkenhaus (при поддержке многих других программистов из сообщества свободного программного обеспечения) и ставший частью проекта GNU не так давно (несмотря на то, что он и до этого лицензировался под GPL). Если отладка не была бы столь трудной работой, мы могли бы поддаться искушению и сказать, что отладка при помощи DDD -- чистой воды удовольствие.
Что же новего предлагает DDD в сравнении с"чистым" gdb или с такими оболочками [frontends] отладчиков, как emacs gud-mode? Главная сила DDD -- не обычные функции отладки, имеющиеся в gdb и поддерживаемые в DDD: пошаговый проход по исходному коду программы строка за строкой, установка точек прерывания и просмотра [breakpoints и watchpoints], изменение значений переменных в процессе выполнения программы. И не то, что в сравнении с традиционным интерфейсом GDB, в DDD доступ к этим возможностям организован более удобным и простым способом. Главное -- это то, что DDD может отображать структуры данных графически. Что это означает? Представьте себе связанный список на C, похожий на тот, что мы будем использовать в одном из последующих примеров. Обычно структура данных состоит из нескольких содержательных полей и одного или нескольких указателей на другие структуры того же типа, из которых образуется взаимосвязанная сеть. Сеть создается установкой правильных адресов в переменных-указателях индивидуальных структур. В принципе, сеть может быть воссоздана по шестнадцатиричным значениям указателей, хранящим информацию о расположении в памяти предыдущего и/или последующего элемента, но это и неудобно, и неприятно. Таким путем трудно получить компактное представление о ситуации в целом, и, даже если программист преуспеет в этом нелегком занятии, остается существенный недостаток: расположение переменных в памяти изменится при следующем запуске программы, при использовании различных входных наборов данных и т.д., что делает проделанную работу бесполезной. DDD преодолевает это ограничение, автоматически создавая по содержимому памяти диаграммы и придавая сложным структурам данных простой и привлекательный визуальный вид.
Способность рисовать структуры данных -- не единственное предлагаемое DDD улучшение классических диалоговых методов отладки:
- Автоматическое переключение между многими файлами с исходным кодом.
- Удобный просмотр исходного кода всей программы, а не только нескольких строк, окружающих определенное выражение.
- Поддержка разных "базовых" [backend] отладчиков. Это означает, что в качестве бак-енд отладчика с DDD может использовать не только gdb, но и отладчики скриптовых языков Python и Perl, отладчик sun java или dbx и ladebug (на системах, отличных от GNU/Linux).
- Поддерживаются разнообразные языки программирования. Это не просто результат поддержки различных отладчиков, но и следствие поддержки в gdb работы с исходными текстами на различных языках -- C, C++, Objective C, Fortran, Java, ... .
- Один и тот-же интерфейс используется для всех языков, поддерживаемых "низлежащими" отладчиками.
Давайте посмотрим, как это все выглядит на практике и отладим несложную программку.
Создание отладочной информации
В двоичном виде программы обычно не содержат какой-либо информации о исходных файлах; они лишь исполняют задачу , закодированную в машинных инструкциях. Поэтому для того, чтобы появилась возможность использовать расширенные функции отладчика, в объектный код необходимо включать отладочную информацию -- так называемые отладочные символы (пошаговый проход по машинным инструкциям будет возможен и без этого, но от этого немного толку, так как нет прямой связи с исходным кодом). В мире Unix используется несколько различных форматов отладочной информации, но мы не будем углубляться в эти вопросы, т.к. это в основном интересно для программистов, занимающихся разработкой компиляторов. Мы сконцентрируемся на платформе GNU/Linux и стандартный компилятор GNU C со стандартными установками.
Обычный способ включения отладочной информации в программу -- указать ключ -g при вызове gcc:
[wolfgang@jupiter wolfgang]$ gcc -g fac.c -o fac
В результате будет создан двоичный файла fac, размер которого окажется больше обычного исполнимого файла. Это, очевидно, не слишком большой сюрприз: т.к. дополнительные данные (о соответствии блоков машинных инструкций и номеров строк исходного кода и т.д.) теперь хранятся в коде, размер файла должен увеличиться.
Полезно заметить, что gcc предлагает возможность, довольно редко встречающуюся у конкурирующих компиляторов: отладочная информация может быть сгенерирована, даже при включенной оптимизации, т.е. команда gcc -g -O2 fac.c fac будет работать, создавая бинарный файл, который и оптимизирован и содержит отладочную информацию. Хотя это может помочь в некоторых случаях, в таком подходе есть несколько скрытых ловушек ( например в результате оптимизации могут исчезнуть несколько строк кода), поэтому такие комбинации мы здесь обсуждать не будем.
Содержимое исходного файла fac.c:
#include<stdio.h>
int main() {
int count;
int fac;
for (count = 1; count < 10; count++) {
fac = faculty(count);
printf("count: %u, fac: %u\n", count, fac);
}
return 0;
}
int faculty(int num) {
if (num = 0) {
return 1;
}
else {
return num * faculty(num - 1);
}
}
Как можно видеть, программа просто выполняет некоторые весьма несложные вычисления: мы перебираем числа из диапазона 1..9 и вызываем функцию вычисления факториала в каждом шаге цикла. Понятно, что это можно сделать эффективнее, но данный вариант служит хорошим примером обычной техники отладки. Кстати: программа не будет работать, т.к. содержит ошибку. Вы можете проверить это запустив ее без присоединенного отладчика (исполнимые файлы, содержащие отладочную информацию запускаются как обычные программы, они просто немного медленнее работают). Единственное, что вы получите -- сброс дампа памяти (core) из за ошибки защиты памяти, пресловутого segmentation fault. Давайте загрузим программу в отладчик и посмотрим, что с ней не так!
Пошаговое выполнение программы
Заргузка программы в отладчик
DDD запускается командой
[wolfgang@jupiter wolfgang]$ ddd&
имя файла, содержащего отлаживаемую программу может быть указано как необязательный аргумент. Если DDD не установлен, то это можно исправить с помощью вашей любимой программы управления пакетами (например, apt-get, rpm и т.д.), т.к. исполнимые файлы DDD включены в большинство дистрибутивов. В случае, если бинарного пакета для вашей системы нет (или если вы,по каким то причинам , хотите самостоятельно собрать DDD с нуля), возьмите дистрибутив с исходным кодом на ftp.gnu.org (или лучше, с одного из зеркал) и следуйте инструкциям в прилагаемом к нему файле INSTALL.
Если имя файла не указано в командной строке, отлаживаемую программу
можно выбрать в диалоговом окне, вызываемом через пункт File->Open
в меню Program. DDD загружает программу, разбирает отладочные символы
(или, если быть точными: позволяет бак-энд отладчику разобрать отладочную
информацию), после чего загружает главный исходный файл. На дисплее
должно появиться окно, похожее на приведенное в рисунке 1
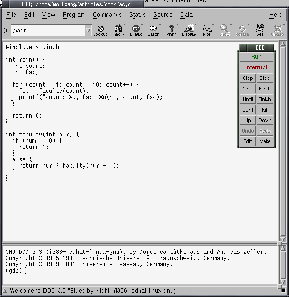
Под-окно "Command Tool'' очень важно для дальнейшей работы.
По умолчанию, оно показывается в области главного окна, и предлагает
несколько кнопок для совершения разнообразных действий с нашим кодом
(в случае, если вы случайно закрыли окно, вы можете открыть его еще
раз при помощи F8 или пункта меню View->Command
Window).
Команды Step и Next
Давайте будем выполнять программу строка за строкой, наблюдая, что же именно происходит во время её выполнения. Чтобы сделать это, нам нужно запустить программу, но нам также требуется создать так называемую точку останова [breakpoint], чтобы предотвратить завершение программы перед тем, как у нас появиться шанс её прервать. Точка останова приостанавливает выполнение программы на определенной строке исходного кода, давая возможность обращаться к отладчику и производить отладочные действия. Направьте курсор мыши на левую сторону окна с исходным кодом (на строку int count;), нажмите правую клавишу мыши и выберите из всплывающего меню команду ''Set Breakpoint''. На соответствующей строке появится красный знак СТОП, означающий, что выполнение программы будет приостановлено, как только достигнет этой точки.Теперь мы можем запустить программу: в command tool выберите ''run'', что заставит отладчик начать выполнение кода. Программа будет выполняться недолго, т.к. точка останова расположена в самом начале файла, теперь мы находимся в интерактивном режиме отладчика. Зеленая стрелка слева от строк с исходным кодом показывает нам ту строку исходного файла, которая будет выполнена следующей.
Есть две возможности ''шагать'' через исходный код: команда ''next'' проводит вас строка за строкой, но "проскакивает" тело вызываемых процедур (просто возвращая результаты вызова) а команда ''step'' будет "прокладывать свой путь" через инструкции, составляющие тело вызываемых процедур. Так как мы хотим увидеть, что же не так с нашей программой (опытные программисты, конечно, уже заметили ошибку, т.к. она очень распространенная), мы решили идти через программу в пошаговом режиме (step). Нажмите кнопку и вы увидите зеленый указатель строки исходного кода в самом начале процедуры faculty. Это то, чего мы и добивались, итак вы можете нажать 'step' еще раз, перепроводя зеленую стрелку прямо в else-ветку нашего блока условий. Что же мы теперь намереваемся получить? Т.к. num имеет значение 1, при входе в процедуру, оно должно быть равно 0, когда мы рекурсивно войдем в процедуру еще раз, вызывая немедленное возвращение числа 1, что в свою очередь выльется в возвращение значения 1*1=1 из нашего первого вызова faculty, возвращая нас назад в основную программу. Давайте проверим, случиться ли это на самом деле, нажав ''step'' еще раз: Зеленый указатель перемещается опять к началу функции, но еще раз заходит в ветку else на следующем шаге! Очевидно, что что-то пошло не так: Нам нужно проверить значение num.
Есть несколько способов выяснить значения простых переменных (т.е.
переменных простых типов, таких, как int, long, float и т.д.). Наиболее
распространенный способ -- подержать указатель мыши над именем переменной
в окне исходного кода, ожидая появления на экране всплывающей подсказки
с её значением. Альтернативные способы: нажать правую клавишу мыши
прямо над идентификатором и выбрать Print num из всплывающего
меню, или пометить идентификатор и выбрать пункт меню Data->Print().
При использовании двух последних методов, значение отображается в
окне вывода gdb внизу главного окна.
Независимо от использованного метода, в качестве значения num мы получаем 0. Почему же исполнялась вторая ветка, если num = 0? Использование step еще раз, подтверждает ваши возможные заключения о причине ошибки: если мы посмотрим на значение num справа, в начале функции, мы увидим, что оно равно -1, но в следующем шаге (опять вторая ветвь условия if), оно опять равно 0: Ошибка -- забытый знак = в условном выражении оператора if, приводящего к присваиванию вместо сравнения! Хотя в программах на C эта ошибка очень часта, оказавшись хорошо запрятаной, она может вызвать длительный простой в разработке. Т.к. от этой некорректно работающей программы мы никогда не получим какого-либо вразумительного результата, то ее можно просто "убить" кнопкой ''kill''.
Исправьте ошибку, заменив "=" на "==", перекомпилируйте программу (не забудьте опять указать компилятору сгенерировать отладочную информацию!) и загрузите её в DDD при помощи меню "File". Как можно видеть, точка останова сохранилась, поэтому мы можем запустить программу снова с самого начала. Теперь, если мы протрассируем faculty, то все будет работать правильно. Функция faculty завершена, и зеленый указатель строки исходного кода теперь на строке printf(...). Следует быть осторожным: если мы используем ''step'' еще раз, DDD попробует пройти через вызов printf, что невозможно, т.к. это функция из стандартной библиотеки C, которая обычно компилируется без отладочной информации (хотя такая возможность существует). Поэтому в данном случае мы предпочтем ''next''. ''Step'' выдаст сообщение об ошибке -- о том, что недостает нескольких исходных файлов -- и, чтобы вернуть зеленый указатель назад к нашему исходному коду, потребуется несколько нажатий на ''next''.
Визуализация структур данных
Простые структуры
В нашем первом, простом примере, DDD не очень отличается от других интерфейсов к отладчику, таких, как gub-mode в emacs (хотя в DDD болеше комфорта). Но у DDD есть уникальная и удивительная возможность: графическое отображение вложенных структур данных. Для того, чтобы продемонстрировать эти возможности, нам понадобиться новая программа list.c:
#include<stdio.h>
int main() {
typedef struct person_struct {
/* Элементы данных */
char* name;
int age;
/* Элементы для организации списка */
struct person_struct *next;
struct person_struct *prev;
} person_t;
person_t *start;
person_t *pers;
person_t *temp;
char *names[] = {"Linus Torvalds", "Alan Cox", "Rik van Riel"};
int ages[] = {30, 31, 32};
int count; /* Временный счетчик */
start = (person_t*)malloc(sizeof(person_t));
start->name = names[0];
start->age = ages[0];
start->prev = NULL;
start->next = NULL;
pers = start;
for (count=1; count < 3; count++) {
temp = (person_t*)malloc(sizeof(person_t));
temp->name = names[count];
temp->age = ages[count];
pers->next = temp;
temp->prev = pers;
pers = temp;
}
temp->next = NULL;
printf("Структура данных создана\n");
return 0;
}
Хотя использованные в этом примере имена могут показаться знакомыми, они не важны. Возраст выбран случайным образом.
В программе создается двусвязный список элементов типа person_t, в которых хранится два параметра (имя и возраст) вместе с двумя указателями (на предыдущую и последующую "персону" в списке). Каждый программист встречался с подобной структурой данных (обычно в более завершенном виде), поскольку она -- из самых важных в C. Как и раньше, наша программа не делает ничего серьезного: просто строит в памяти структуру данных и завершает выполнение, но для наших целей этого вполне достаточно. Как обычно, программу нужно скомпилировать с отладочной информацией, а затем загрузить в DDD.
На этот раз мы запустили программу с первой точкой останова в строке 28 (начало цикла for). Поместите указатель мыши над идентификатором start и через некоторое время DDD покажет всплывающую подсказку с 16-ричным значением этого указателя на структуру типа struct person_t, находящуюся по определенному адресу в памяти. Великолепный кандидат для графической визуализации!
Щелчком правой кнопки мыши над идентификатором start вызовите контекстное меню и выберите "Display *start" -- звездочка нужна для того, чтобы DDD автоматически разыменовывал указатель и показывал содержащиеся в структуре данные. В верхней части окна DDD появится новая секция с иллюстрацией, изображающей содержимое start: name и age содержат значения, присвоенные несколькими строками кода раньше, а next и prev -- указатели NULL, как и должно быть. Рисунок 2 показывает окно, которое вы должны увидеть на дисплее (хотя шестнадцатиричное значение указателя char* в вашей системе может быть другим).
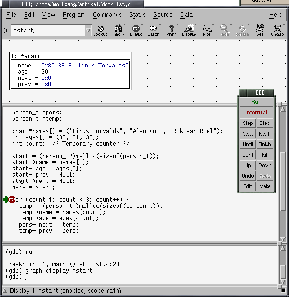
Такая возможность впечатляет сама по себе, не так ли? Но давайте
позволим нашей прогамме поработать еще немного и посмотрим, как в
памяти строится структура данных. С помощью кнопки ''next'' пройдем
через тело цикла до строки 34 (pers->next = temp):
здесь создается вторая структура person, которая затем соединяется
с первой. Если после этого взглянуть на графическое представление,
то можно увидеть, что значение поля next в нашей первой структуре
теперь отлично от 0. Это означает, что оно указывает на другую структуру.
Итак, внимание... Если дважды щелкнуть на этом поле, то в появившейся
рамке будет отображено содержимое второй структуры, а указатель от
person 1 к person 2 будет автоматически изображен в виде стрелки.
Для создания структуры данных третьей "персоны" мы используем другой путь, т.к. неудобно выполнять код строка за строкой лишь для того, чтобы просто увидеть результат его выполнения. Создадим еще одну точку останова на строке 39, в которой находится вызов printf(...). Нажатие ''cont'' продолжит выполнение программы до следующей точке останова (мы её только что установили).
Структуру с данными третьей "персоны" мы можем отобразить обычным путем. Но теперь мы хотим не просто увидеть указатели от person n к person n+1, но и отобразить обратные указатели! Например, щелкните дважды на поле prev на изображении второй структуры: "всплывет" еще одна рамка, дублирующее рамку с содержимым первой структуры person! То же произойдет с указателем prev в структуре данных "третьей персоны". Это, очевидно, не совсем то, что мы хотели, т.к. структура не должна отображаться дважды. Мы должны как-то сказать DDD, чтобы он позаботиться об этом.
В DDD есть специальная функция, называемая выявление псевдонимов
[alias detection], которая активируется пунктом Data->Detect
в меню Aliases. На дисплее должно появится примерно тоже, что и на
рисунке 3.

Все указатели изображены правильно и дают достаточно полную картину расположения в памяти структуры данных. К сожалению, выявление псевдонимов замедляет работу DDD, особенно на сильно связанных структурах, т.к. для того, чтобы выяснить, какие структуры на дисплее представляют одни и те же области памяти (соответственно уменьшая число элементов диаграммы), необходимо сравнить несколько адресов памяти после каждого шага программы. Кроме того, alias detection работает только с языками, позволяющими работающему "за спиной" DDD отладчику получать адреса памяти произволных объектов, что на данный момент ограничивает выбор языками C, C++ и Java.
Более сложный пример
Чтобы продемонстрировать возможности DDD по автоматическому размещению и выравниванию диаграмм, давайте разберем несколько более сложный пример (во всяком случае, в отношении создаваемой структуры данных). Исходный текст примера (arith.c) приведен ниже:
#include<stdio.h>
/*
* Создает структуру бинарного дерева,
* представляющую арифметическое выражение
*/
enum operator { plus, minus, times, div };
typedef struct tree_struct {
struct tree_struct *left;
struct tree_struct *right;
union {
int op:2;
int val;
} opval;
} tree_t;
int main() {
tree_t *node;
tree_t *root = (tree_t*)malloc(sizeof(tree_t));
root->opval.op = times;
node = (tree_t*)malloc(sizeof(tree_t));
node->right = NULL;
node->left = NULL;
node->opval.val = 7;
root->right = node;
node = (tree_t*)malloc(sizeof(tree_t));
node->opval.op = plus;
root->left = node;
node = (tree_t*)malloc(sizeof(tree_t));
node->left = NULL;
node->right = NULL;
node->opval.val = 5;
root->left->left = node;
node = (tree_t*)malloc(sizeof(tree_t));
node->left = NULL;
node->right = NULL;
node->opval.val = 3;
root->left->right = node;
printf("Дерево создано\n");
return 0;
}
Программа создает дерево, представляющее арифметическое выражение в том виде, в котором его видят компиляторы после завершения процедуры синтаксического разбора: круглые скобки в такой форме излишни, т.к. эта информация содержится в самой структуре графа. Каждый узел соответствует арифметическому оператору (плюс, минус, умножение или деление, как определено в перечислении operators) или целочисленное значение. Представленное структурой данных вырожение в явном виде выглядит так: (5+3)*7
Запустите программу (задав точку останова после окончания построения структуры данных, но до завершения программы), получите графическое изображение корневого элемента и откройте все последующие элементы, дважды щелкнув на элементах структуры left/right. Так можно получить всю информацию о размещении структуры в памяти, но схема выглядит не слишком-то красиво. Мы хотим привести её к виду, показанному на рисунке 4:
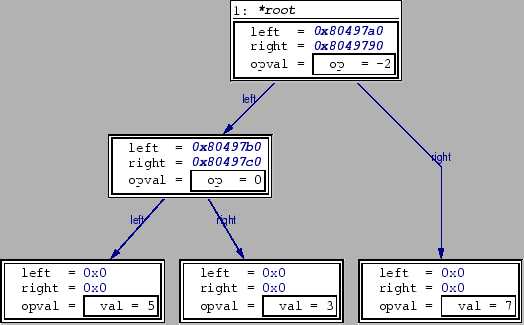
Разница с картиной, полученной простым разворачиванием структуры,
очевидна: все элементы располагаются в соответствии с уровнями дерева.
Конечно, этого можно достичь и перетаскиванием элементов с места на
место при помощи мышки, но это не слишком удобно: предоставляемая
DDD возможность автоматического размещения намного проще, во всяком
случае, для пользователя. Чтобы ее использовать, просто выберите пункт
меню Data->Layout Graph (или воспользуйтесь комбинацией
клавиш ALT+Y). DDD расположит диаграммы, как показано выше.
Заметьте что в диаграмме были вручную сделаны дополнительные изменения. Т.к. для представления в узле либо значения, либо оператора мы используем объединение [union], DDD отображает сразу обе возможности. Этого следует избегать, поскольку может возникнуть путаница. Правила просты: если оба указателя left и right установлены в NULL, узел представляет число, иначе оператор. Для того, чтобы удалить с изображения нежелательный элемент, выберите из контекстного меню (щелчком правой кнопкой мыши) пункт ''Undisplay''. DDD спросит, следует ли применять действие ко всем подходящим структурам или только к текущей; а поскольку в разных рамках мы хотим удалить различные "ипостаси" объединения, то следует выбрать второй вариант.
В меню данных DDD предлагает и некоторые дополнительные возможности, относящиеся к расположению диаграмм. Они достаточно интуитивны, так что читатель сам очень быстро поймет, как ими пользоваться.
Множественно связанные структуры
В качестве последнего примера (и еще одной демонстрации громадных возможностей, предлагаемых DDD), посмотрите на иллюстрацию 5: Она показывает диаграмму, созданную программой poly.c, реализующей представление полинома (3*x^2+zy-3xy^3), используя структуру данных, описанную в классической работе Основные алгоритмы (из трехтомника Искусство программирования Дональда Кнута). Вы не обязаны сразу понять смысл диаграммы... Просто получите впечатление о возможностях визуализации достаточно сложных структур, которые непросто понять, имея на руках лишь исходный код. Заметьте, что для данной диаграммы автоматическое размещение не использовалось, т.к. оно производит правильное, но не слишком информативное представление: в графическое представление структуры данных нужно "вложить" очень много информации об идеях, на которых эта структура основана.
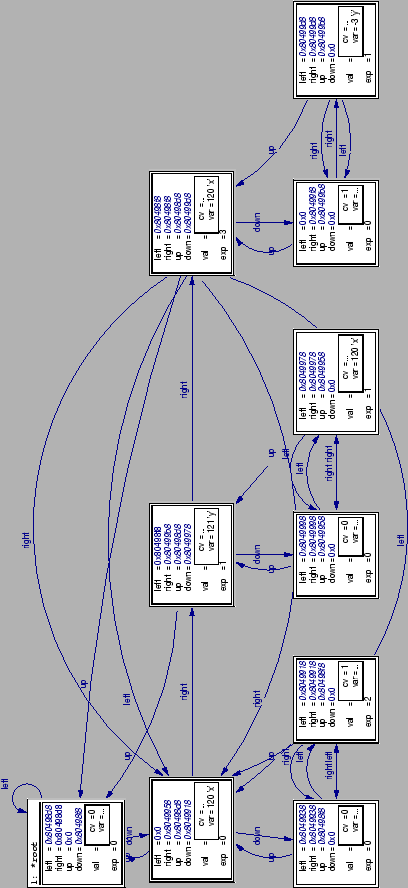
Визуализация наборов данных
Структуры данных -- не единственное, что может визуализировать DDD: при помощи хорошо известной программы Gnuplot (в качестве вспомогательного средства) можно визуализировать данные, хранящиеся в массивах. Поскольку такие данные довольно часто требуется в научных программах, мы специально рассмотрим эту удобную возможность.Программа в файле valtab.c, создает таблицу значений определенной функции (в данном случае двумерной функции sin). Заметьте, что для компилящии этой программы нужно передавать gcc ключ -lm, который подключает математическую библиотеку!
#include<stdio.h>
#include<math.h>
int main() {
float *val;
float sval[100];
float **threed;
int points = 100;
float period = 2*M_PI;
int count, count2;
val = (float*) malloc(points*sizeof(float));
for (count = 0; count < points; count++) {
val[count] = sin(count * period/(float)points);
sval[count] = val[count];
}
threed = (float**)malloc(points*sizeof(float));
float x,y;
for (count = 0; count < points; count++) {
threed[count] = (float*)malloc(points*sizeof(float));
for (count2 = 0; count2 < points; count2++) {
x = count*period/(float)points;
y = count2*period/(float)points;
threed[count][count2] = 1.0f/(x+y)*sin(x+y);
}
}
/*
* Вообще говоря, мы бы записали сгенерированные данные в файл
* или что то в этом роде...
*/
printf("Таблица данных создана\n");
return 0;
}
Большинство "настоящих" программ будут работать с более сложными функциями (или получать наборы данных другим путем), но основной принцип (занесение неких значений в массив), остается неизменным во всех случаях.
Для того, чтобы продемонстрировать различные методы визуализации
данных, в нашем примере мы используем три вида массивов. Простейший
вариант -- статический одномерный массив, как показано в sval.
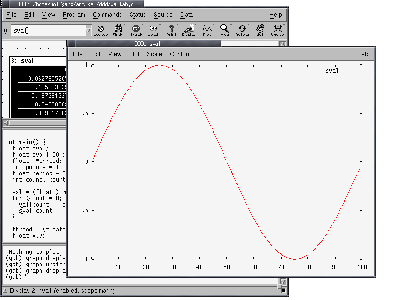
В этом случае нам нужно только выделить идентификатор, щелкнув на
нем правой клавишей , и нажать на иконку ''plot'', которую можно найти
в верхней части окна -- вуаля!, открывается новое окно gnuplot с нужным
графиком. Вид диаграммы можно настроить при помощи нескольких пунктов
меню; рисунок 6 показывает изображение, со стилем ''lines'' вместо
используемого по умолчанию стиля ''points'', что достигается при помощи
пункта меню Plot->Lines.
В случае динамически создаваемых массивов ситуация в некоторой степени усложняется, т.к. DDD не может автоматически определить их размер. Обходный путь -- использование так называемых срезов массива (array slices), которые нужно определить вручную в предназначенной для взаимодействия с отладчиком части нижней половины главного окна DDD.
Выражение graph display val[0]@points создает срез
массива, где индексное выражение [0] задает нижнюю границу
используемых значений, а @points -- верхнюю (вместо значения переменной
points можно просто использовать целое число). Визуализация
графика осуществляется так же, как и раньше (нажатием кнопки ''plot'')
и дает (сюрприз, сюрприз) тот же результат, поскольку используются
идентичные наборы данных.
Построение 3-х мерных диаграмм работает похожим образом: надо просто
выделить мышкой идентификатор статического массива, после чего воспользоваться
кнопкой ''plot'', а если используются динамические структуры, то создать
срез массива. Как вы можете предположить, для этого используется такой
синтаксис: graph display threed[0][0]@points@points.
Т.к. доступные в gnuplot возможности точной настройки 3-мерных диаграмм не слишком хорошо поддерживаются интерфейсом DDD, по сравнению с визуализацией 2-мерных массивов эти попытки обычно дают не слишком хорошие и/или осмысленные результаты.
Распечатка диаграмм и графиков.
Иногда, чтобы документировать работу программы, удобно получить графическое представление структур данных в том виде, в каком их создает DDD. Интерфейс печати предлагает возможность создания Postscript версий диаграмм и графиков. Чтобы распечатать диаграмму выберите командуFile->Print
Graph. В появившемся меню с несколькими опциями нажатие клавиши
print создаст файл или пошлет выходные данные непосредственно на принтер.
Тот же самый метод может быть использован для графиков; единственное различие -- в диалоге печати меньше опций. В то время, как диаграммы могут быть экспортированы как в PostScript, так и в формат fig (используемый классической векторной программой рисования для Unix -- xfig), графики можно экспортировать только в Postscript.
В DDD есть множество других возможностей, таких как точки просмотра -- watchpoints, поддержка разных языков программирования и т.д. Эти возможности выходят за рамки темы данной статьи, и мы не ставим целью повторять содержание прекрасной документации, поставляемой вместе с DDD (ее можно найти по адресу http://www.gnu.org/software/ddd). Вместо этого, мы предлагаем читателям самостоятельно исследовать широкий набор возможностей DDD, отлаживая собственные программы.
Последнее замечание: не забывайте фразу, которую DDD показывает как "совет дня", которая очень хорошо отражает важность (и ограниченность) отладки:
Отладчик не заменит хорошего обдумывания. Но в некоторых случаях обдумывание не заменит хорошего отладчика. Самая эффективная комбинация -- и хорошее мышление и хороший отладчик --Steve McConnell, Code Complete
Wolfgang Mauerer
Wolfgang написал на немецком языке книгу Textverarbeitung mit LaTeX unter Unix. Иногда он сотрудничает (как технический писатель) с немецким изданием Linux Magazin, и работает в небольшой немецкой веб-компании MyNetix, где выполняет обязанности программиста и системного администратора.
Copyright (C) 2001, Wolfgang Mauerer.
Copying license http://www.linuxgazette.com/copying.html
Published in Issue 73 of Linux Gazette, December 2001
Вернуться на главную страницу