Установка онлайнового словаря dict
Автор: © Chris Gibbs
Перевод: © Сергей Скороходов.
Для чего писалась эта статья
Для того, чтобы рассказать о значительной работе, выполненной и выполняемой на http://www.dict.org и помочь пользователям Linux, независимо от их квалификации, установить работоспособную систему словарного поиска на своем компьтере или сервере сети.
СОДЕРЖАНИЕ
- Введение
- Группа разработки DICT (www.dict.org)
- Имеющиеся словари
- Установка
- dictd, dict and dictzip
- Словарь Вебстера
- ВордНет 1.6
- Файл Жаргона, FOLDOC, Элементы, Библейский словарь Истона и Словарь библейских имен Хичкока
- Обновленный Файл Жаргона
- US Gazetteer
- Чертов Словарь
- Кто Есть Кто: от 5000 г. до Рождества Христова и до наших дней
- Языковые словари
- Конфигурация dictd
- Использование dict
- Kdict
- Заключение
Введение
Я работаю исключително под операционной системой Linux уже более трех лет. Одна из немногих вещей, которых мне недоставало по сравнению с "той другой операционной системой" -- это доступность дешевых, а зачастую и бесплатных версий коммерческих энциклопедий и словарей.
Так что, установив свежую версию S.u.S.E. Linux я был приятно удивлен, обнаружив на своей машине пакет Kdict. Из сопровождающей документации стало ясно, что это лишь оболочка для другой программы, и что, если я пожелаю установить локальный сервер словарного поиска, все нужные компоненты пришлось бы доставать в Интернете.
Группа разработки DICT [DICT Development Group] (www.dict.org)
Замечание: Этот раздел просто пересказывает содержание файла ANNOUNCE из дистрибутива dict.Группой разработки DICT [The DICT Development Group (www.dict.org)] созданы описанный в RFC 2229 протокол словарного поиска [Dictionary Server Protocol], серверное и клиентское программное обеспечение на C, клиенты на других языках (Java и Perl), а также ей выполнена конвертация имеющихся бесплатных словарей в формат, используемый собственными программами.
Протокол словарного поиска (DICT) основан на TCP и определяет транзакции для выполнения запросов и получения ответов, открывающий клиенту доступ к словарным статьям из набора словарных баз данных на естественном языке. Минимум программного обеспечения включает:
Клиентская утилита коммандной строки dict(1) для доступа к DICT-серверу.
DICT-сервер dictd(8), обеспечивающий поддержку протокола на серверной стороне.
Утилита dictzip(1) для сжатия файлов в формате gzip (RFC 1952). Однако, в отличие от gzip(1), dictzip(1) при сжатии разбивает файлы на блоки и сохраняет индекс блоков в gzip-заголовке. Это дает возможность произвольного доступа к блокам сжатого файла (в настоящее время размер блока около 64 kB) при сохранении коэффициента сжатия в пределах 5% от получаемого при стандартной компрессии. dictd(8) использует сжатые файлы в этом формате.
Собственно словарные данные, программы для преобразования и форматированного вывода для нескольких свободно распростарняемых словарей доступны в виде отдельных .tar.gz файлов. Условия коммерческого распространения каждого такого словаря могут отличаться от условий распространения для некоммерческого ипользования, так что обязательно прочтите лицензионную информацию в начале файла каждой базы данных. Ниже приводятся приблизительные размеры каждой базы данных, число словарных статей в ней и необходимое для работы с базой данных дисковое пространство.
| Словарь | Число словарных статей | Размер индекса | Размер данных | Размер в распакованном виде |
| web1913 |
185399
|
3438 kB
|
11 MB
|
30 MB
|
| wn |
121967
|
2427 kB
|
7142 kB
|
21 MB
|
| gazetteer |
52994
|
1087 kB
|
1754 kB
|
8351 kB
|
| jargon |
2135
|
38 kB
|
536 kB
|
1248 kB
|
| foldoc |
11508
|
220 kB
|
1759 kB
|
4275 kB
|
| elements |
131
|
2 kB
|
12 kB
|
38 kB
|
| easton |
3968
|
64 kB
|
1077 kB
|
2648 kB
|
| hitchcock |
2619
|
34 kB
|
33 kB
|
85 kB
|
| www |
587
|
8 kB
|
58 kB
|
135 kB
|
В скомпрессированном виде все базы данных и индексы требуют для своего размещения примерно 32MB дискового пространства.
Дополнительно имеется некоторое количество двуязычных словарей, полезных для переводчиков. Хотя я их не смотрел, судя по разному размеру, разные словари имеют неодинаковую ценность (например, Англо-Уэльский словарь, к сожалению, не слишком хорош, в то время, как Англо-Немецкий по-видимому, может оказаться весьма полезным).
Создается впечатление, что все словари находятся в непрерывном развитии, так что следите за обнавлениями.
Имеющиеся словари
- Полный Словарь Вебстера -- Webster's Revised Unabridged Dictionary (1913 г.)
- Вы скажете, что это Oxford English Dictionary, так именно нет! Но мил! Судя по всему, это американская версия тех энциклопедических словарей, которые были столь популярны в то время. Нередко в словарной статье можно найти поэтическую цитату, а в целом словарь очень содержательный и приятный в испольпользовании.
-
ВордНет -- WordNet (r) 1.6 - Этот словарь, видимо, находится в бесконечной разработке. Создавался, судя по всему, с целью предоставить все, какие только можно пожелать, определения для всех мыслимых слов. На практике в нем, похоже, отсутствуют определения некоторых очевидных слов вроде "with" и "without". Подозреваю, что создатели думали просто о необходимом обновлении словаря Вебстера. Если Вам нужен словарь посовременнее, то без него не обойтись.
-
Свободный онлайновый словарь по компьютерной технике -- The Free On-line Dictionary of Computing (от 15 февраля 1998 г.) - FOLDOC представляет собой снабженный возможностями поиска словарь акронимов, жаргона, языков программирования, инструментальных средств, архитектур, операционных систем, сетевых технологий, теорий, соглашений, стандартов, математических концепций, коммуникационных технологий, электроники, учреждений, компаний, проектов, продуктов, исторических сведений, по сути всего, относящегося к вычислительной технике. Copyright Denis Howe 1993, 1997.
-
Словарь U.S. Gazetteer (1990 г.) - Ну это, вероятно, заинтетерсует только тех, кто нуждается в сведениях об Америке. Оригинальные файлы U.S. Gazetteer Place and Zipcode (списки с именами городов, улиц и т.д. и соответствующих почтовых индексов) предоставленные в общее пользование U.S. Census Bureau (В США -- Бюро Переписи Населения).
-
Библейский словарь Истона 1897 года -- Easton's 1897 Bible Dictionary - Этот словарь содержит разделы из третьего издания Иллюстрированного Библейского словаря М.Г. Истона [M.G. Easton M.A., D.D., Illustrated Bible Dictionary, Third Edition], изданного Томасом Нельсоном [Thomas Nelson] в 1897 году. Природа электронного текста не позволила включить иллюстрации.
Словарь библейских имен Хичкока -- Hitchcock's Bible Names Dictionary (конец XIX века)- Составлен на основе Хичкоковского "Нового и Полного Анализа Святой Библии", увидевшего свет в конце XIX столетия. Содержит более 2 500 библейских и имеющих отношение к Библии имен с их объяснениями. Некоторые древнееврейские слова с неясными значениями опущены. Вне действия копирайта, так что можете свободно копировать и распространять. (Молю Господа, дабы посредством словаря сего облегчил Вам постижение Слова Его! -- Брад Хогард [Brad Haugaard]).
-
Элементы -- The Elements (от 22 октября 1997 г.) - Словарная база данных, созданная Джеем Коминеком [Jay Kominek] <jfk at acm.org>.
-
The CIA World Factbook (1995 г.) - Довольно типичное и ограниченное описание мира (уж простите, я люблю Америку, я достаточно долго жил в Америке, но Америка -- не ВЕСЬ МИР!), может принести пользу только обнаруживаемыми в предметном указателе ссылками на Приложения, которые с некоторыми ограничениями могут быть использованы нормальными, уверенными в том, что мир не существует за пределами клавиатуры, людьми.
Файл Жаргона --Jargon File (версия 4.2.0 от 31 января 2000 г.)- Полное собрание хакерского слэнга, освещающее многи аспекты хакерской традиции, фольклора и юмора. Заметно похоже на FOLDOC, описанный выше.
ЧЕРТОВ СЛОВАРЬ -- THE DEVIL'S DICTIONARY (Copyright 1911 г., вышел 15 апреля 1993)- Чертов Словарь начал свое существование в 1881 году в виде еженедельного издания и был продолжен в виде редких и разрозненных публикаций вплоть то 1906 года. В 1906 году был издан в виде книги под названием Словник Циника, автор этих строк не обладает ни властью дезавуировать это название, ни счастьем подтвердить его соответствие содержанию. Пользователи программы fortune должны бы уже иметь представление;-)
Кто Есть Кто -- Who Was Who- Кто Есть Кто: от 5000 г. до Рождества Христова и до наших дней: Библиографический словарь знаменитостей и тех, кто хотел бы быть знаменитостью, под редакцией Ирвина Л. Гордона [Irwin L. Gordon].
ПРОЧИЕ СЛОВАРИ- Имеется еще несколько словарей, за деталями обращайтесь к домашней странице dict. Во многих случаях Вы обнаружите, что программа, необходимая для конвертации в необходимый для dict формат еще не написана ;-(
Как уже говорилось, имеется несколько двуязычных словарей (см. далее).
Установка
Все ссылки работали во время написания статьи. Если с момента опубликования статьи прошло значительное время, Вам следует посетить http://www.dict.org и посмотреть, что изменилось.
К сожалению, установка упомянутого программного обеспечения, проходит не столь гладко, как хотелось бы, что отчасти и побудило меня к написанию данного опуса ;-)
Для начала Вам потребуется изрядный кусок дискового пространства. Словарь Вебстера 1913 года -- самый крупный и требует для пересборки около 85 мегабайт на диске.
dictd, dict and dictzip
Распакуйте файл dictd-1.5.5.tar.gz как обычно.
ВАЖНОЕ ЗАМЕЧАНИЕ: Поддержка HTML в данной версии dict отключена. Вам придется заново включить ее для того, чтобы воспользоваться преимуществами Kdict.
Загружите файл dict.c в свой любимый текстовой редактор и раскомментируйте строку 1069:
{ "raw", 0, 0, 'r' },
{ "pager", 1, 0, 'P' },
{ "debug", 1, 0, 502 },
{ "html", 0, 0, 503 }, // Раскомментируйте эту строку
{ "pipesize", 1, 0, 504 },
{ "client", 1, 0, 505 },
текст должен выглядеть так, как показано.
Теперь можно выполнить ./configure;make;make install. Сами увидите, как много предупреждений выдаст компилятор, но в результате у Вас должны получится работоспособный клиент, сервер и утилита сжатия данных.
Словарь Вебстера
Распакуйте dict-web1913-1.4.tar.gz и web1913-0.46-a.tar.gz:
$ tar xvzf dict-web1913-1.4.tar.gz $ tar xvzf web1913-0.46-a.tar.gz $ cd dict-web1913-1.4 $ mkdir web1913 $ cp ../web1913-0.46-a/* web1913 $ ./configure $ make $ make db
Сделайте большую чашечку чая: на моем 133 мегагерцовом пне это заняло более часа. По завершению примите решение, где поселить словари и скопируйте их туда. Я воспользовался рекомендуемой директорией /opt/public/dict-dbs:
$ mkdir /opt/public/dict-dbs $ cp web1913.dict.dz /opt/public/dict-dbs $ cp web1913.index /opt/public/dict-dbs
ВордНет 1.6
Берется dict-wn-1.5.tar.gz.
Достойно сожаления, что один из наиболее полезных словарей отказывается компилироваться без ошибок. Для создания жизнеспособного словаря оригинальные данные необходимо обработать специальной программой. Именно она и создается командой make. К несчастью, Makefile , созданный ./configure из этого пакета не работает. Исправить процедуру automake мне не удалось, но это, уверяю Вас, сработает:
$ tar xvzf dict-wn-1.5.tar.gz $ cd dict-wn-1.5 $ ./configure $ gcc -o wnfilter wnfilter.c $ make db
Опять же -- процесс не быстрый (> часа на моем 133). По завершению, создайте директорию для словарей (если не сделали этого раньше) и скопируйте туда полученный словарь и индекс:
$ cp wn.dict.dz /opt/public/dict-dbs $ cp wn.index /opt/public/dict-dbs
Файл Жаргона, FOLDOC, Элементы, Библейский словарь Истона и Словарь библейских имен Хичкока
Берется dict-misc-1.5.tar.gz$ tar xvzf dict-misc-1.5.tar.gz $ cd dict-misc-1.5 $ ./configure $ make $ make db $ cp easton.dict.dz /opt/public/dict-dbs $ cp easton.index /opt/public/dict-dbs $ cp elements.dict.dz /opt/public/dict-dbs $ cp elements.index /opt/public/dict-dbs $ cp foldoc.dict.dz /opt/public/dict-dbs $ cp foldoc.index /opt/public/dict-dbs $ cp hitchcock.dict.dz /opt/public/dict-dbs $ cp hitchcock.index /opt/public/dict-dbs $ cp jargon.dict.dz /opt/public/dict-dbs $ cp jargon.index /opt/public/dict-dbs
Обновленный Файл Жаргона
Берется dict-jargon-4.2.0.tar.gz$ tar xvzf dict-jargon-4.2.0.tar.gz $ cd dict-jargon-4.2.0 $ ./configure $ make $ make db $ cp jargon.dict.dz /opt/public/dict-dbs $ cp jargon.index /opt/public/dict-dbs
US Gazetteer
Берется dict-gazetteer-1.3.tar.gz$ tar xvzf dict-gazetteer-1.3.tar.gz $ cd dict-gazetteer-1.3 $ ./configure $ make $ make db $ cp gazetteer.dict.dz /opt/public/dict-dbs $ cp gazetteer.index /opt/public/dict-dbs
Чертов Словарь
Берется devils-dict-pre.tar.gz
Как и в случае описанных ниже языковых словарей, словарный файл уже создан. Просто распакуйте файлы в нужную директорию.
Кто Есть Кто: от 5000 г. до Рождества Христова и до наших дней
Берется http://www.hawklord.uklinux.net/dict/www-1.0.tgz$ tar xvzf www-1.0.tgz $ cd www-1.0 $ ./configure $ make $ make db $ cp www.dict.dz /opt/public/dict-dbs $ cp www.index /opt/public/dict-dbs
Языковые словари
Навестите ftp://ftp.dict.org/pub/dict/pre/www.freedict.de/20000906
Установка языковых словарей не подразумевает пересборки словарных файлов из оригинальный данных, Вам просто нужно распаковать каждый файл в словарную директорию.
Конфигурация dictd
dictd ожидает обнаружить файл /etc/dictd.conf, хотя в командной строке можно указать альтернативу. В нем нужно указать каждый словарь для того, чтобы dictd мог найти сам словарь и соответствующий индексный файл. Например, если Вы просто хотите работать со словарем Вебстера, ВордНет и Чертовым Словарем, то потребуются следующие пункты (в предположении, что для размещения словарей используется директория /opt/public/dict-dbs).
database Web-1913 { data "/opt/public/dict-dbs/web1913.dict.dz"
index "/opt/public/dict-dbs/web1913.index" }
database wn { data "/opt/public/dict-dbs/wn.dict.dz"
index "/opt/public/dict-dbs/wn.index" }
database devils { data "/opt/public/dict-dbs/devils.dict.dz"
index "/opt/public/dict-dbs/devils.index" }
Более сложная конфигурация
По-видимому, возможно управлять правами доступа для пользователей и предпринять другие меры безопасности. Я не пробовал. Если бы меня интересовали вопросы безопасности, то программа в ее теперешнем виде не дает даже малейших оснований доверять каким-либо встроенным в нее функциям безопасности. Впрочем, нужда в ограничении доступа к этим словарям находится за пределами моего разумения, т.к. по определению словари предназначены для всеобщего пользования.
Тем не менее, если Вы собираетесь открыть доступ к dictd по локальной сети, то следует иметь в виду несколько связанных с безопастностью моментов т.к. иначе сервер останется незащищенным по нескольким направлениям.
Если Вы не устанавливаете dictd на сервер в школе или колледже (или в другой большой сети), то сильно задумываться о сказанном ниже не придется. Впрочем, если уж Вы устанавливаете словари в действительно большой сети, то Вы уже и так в курсе подобных проблем.
Перегрузка сервера, получение отказов на запросы, чрезмерный своппинг
Все эти симптомы возможны, если сразу много пользователей направят запросы наподобие MATCH * re . Такие запросы возвращают индекс почти для всей базы данных и каждому потребуется 5MB буфер на сервере.
Возможными решениями может быть ограничение числа одновременных подключений к серверу, ограничения размера данных, возвращаемых по запросу и ограничение числа одновремено проводимых операций поиска [outstanding searches].
Отказ от обслуживания (DoS)
Сервер может остановить любой злонамеренный взломщик, вздумающий установить 1000000 подключений сразу.
Для предотвращения подобного антиобщественного поведения ограничьте число подключений по адресу IP или маске.
Переполнение буфера
Если у Вас возникают такого рода проблемы, то следует использовать более надежные процедуры для лога [logging routines], использовать strlen и изучить daemon_log.
Использование dict
dict ищет файл /etc/dict.conf. Этот файл должен содержать строку с именем машины, которую Вы планируете использовать как сервер dictd, хотя это можно изменить из командной строки.
Использование текущей версии dict для доступа к dictd разочаровывает. Если Вы ограничены консолью и не можете воспользваться Kdict -- привыкайте. Худшее свойство dict -- программа может легко "попортить" консоль, после чего скорее всего придется перезапустить консоль для восстановления работы клавиатуры! Такое обычно случается, когда есть проблемы с dictd, например, когда делается попытка использования dict, а dictd не запущен.
Т.к. dict -- консольное приложение, он просто посылает свой вывод less. Так что, если Вы не обладаете феноменальной памятью, переносить слова и фразы обратно в командную строку придется через 'cut and paste'.
Имеется опция для переноса вывода dict в странично ориентированную программу. Я пробовал команду dict -html -P lynx luser, результат оказался удручающим! Lynx свихнулся, показывая случайные страницы справки и файлы конфигурации, что напомнило мне некоторые вирусы для операционных сетей от MS.
Я бы посоветовал: можешь обойтись без использования dict напрямую -- обойдись! Однако, dict необходим для Kdict, а работать с Kdict Вам непременно захочется.
Kdict
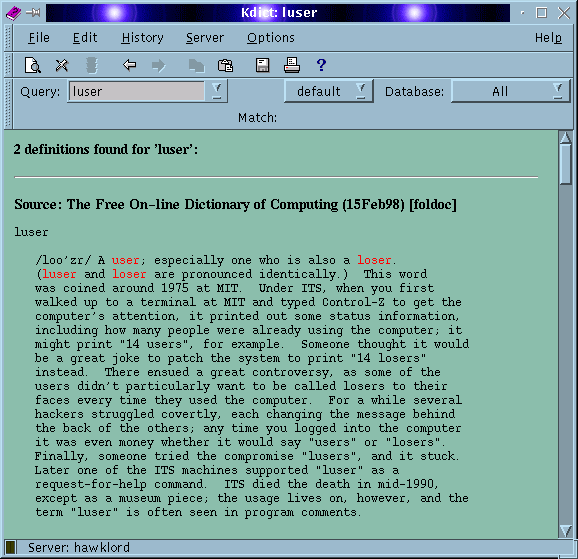
Для эффективного использования dict Вам непременно потребуется Kdict с сайта http://www.rhrk.uni-kl.de/~gebauerc/kdict. У меня версия 0.2, про другие сказать ничего не могу.
Для работы с Kdict Вам не обойтись без поддержки HTML в dict (см. выше).
На картинке показан Kdict "в процессе". Kdict неплохо использует скудные HTML теги, предоставляемые dict, и добавляет свои собственные для улучшения видимости перекрестных ссылок. Все, что выделено красным, можно кликнуть мышью и увидеть определение слова или фразы.
Особенно приятно то, чтоKdict позоволяет использовать буфер обмена для того, чтобы выделить слово в любом окне на рабочем столе и вставить его в запрос Kdict.
Заключение
Это прекрасный проект, который будет только улучшаться со временем, так что он совсем как Linux и другие программы gnu... Поддержите его!
Если вы пользуетесь xscrabble с домашней страницы Матта Чапмена, удовольствие можно увеличить, находя определения незнакомых слов - компьютер даcт вам проср***ся;-).
Copyright © 2001, Chris Gibbs.
Copying license http://www.linuxgazette.com/copying.html
Published in Issue 63 of Linux Gazette, Mid-February (EXTRA) 2001
Вернуться на главную страницу